40× faster ingest in a weekend (and chasing the bottleneck all the way down to Postgres)
Notes from a weekend spent profiling Provenance’s submission ingest, finding an O(n²) bug that was hiding in plain sight, and chasing the cost around the pipeline until it finally landed on the database.
So. This was a weekend.
Provenance records a tamper-evident log of how a student actually wrote their code, and then ingests those logs: parse the bundle, match it to a roster, run heuristics, compute stats, and cross-check across the cohort. The question I wanted answered was simple: can this thing actually handle a real class?
The part where I was delighted
I built a fixture that modeled a real Gradescope export, 700 students with one bundle each, and ran the ingest. About a second per bundle, ~10 minutes for the whole class. I was pretty pleased with myself.
Then I noticed each of those 700 bundles only had about 20 events in it. A student who’d barely typed. So, just for the memes, I made one fixture with 50,000 events, roughly a 4-hour working session, which is extremely possible on a real project.
That was a worse idea than it sounds. Time ballooned. A single 50k-event bundle took about two minutes to ingest. If 700 students each turned in something that size, that’s north of 23 hours of ingest for one assignment, which is obviously not a thing you can hand to course staff.
The hunt
I’d built a little profiler earlier, gated behind an env flag so it’s a no-op in prod,1 so I switched it on to see where the two minutes were going. Most of it was in heuristics, with stats close behind and validation trailing:
$ INGEST_PROFILE=1 npm run profile:large -- 50000
─── ingest profile · one 50k-event bundle ───
phase total share
parse_bundle 0.21s 0.2%
materialize_events 2.50s 1.9%
run_validation 15.60s 11.8%
compute_stats 47.70s 36.0%
run_heuristics 66.30s 50.0%
──────────────────────────────────────────
handler_total 132.50s
Then I ran a 10k-event bundle to check the scaling. The time dropped by about 24×, not the 5× you’d expect from 5× fewer events. That’s the signature of quadratic time, and it wasn’t one stage, it was three of them (heuristics, stats, and validation) all scaling like O(n²).
I’ll be honest about this part: I spent hours here. I tried to get Claude to find it agentically and it kept confidently pointing at the blob-storage step, which the profiler plainly showed was not the problem. So I gave up on that and read every function that runs on ingest by hand.
It turned out to be the file-reconstruction code, the part that replays a session’s edits to rebuild what the file looked like at each step. There was a helper that converted an editor position into a string offset, and it looked like this:
function positionToOffset(content: string, line: number, character: number): number {
const lines = content.split('\n'); // ← O(file length), on EVERY call
let offset = 0;
for (let l = 0; l < line; l++) offset += lines[l].length + 1;
return offset + character;
}
content.split('\n') over the entire current file body, called twice for every edit (once for the start of the change, once for the end), inside the replay loop. The file grows as you replay it, so you’re splitting a longer and longer string on each of n events, which is where the O(n²) comes from. The same helper had also been copy-pasted (oh dear) into three files that have to stay in lockstep,2 so it was really three quadratics wearing a trench coat.
The fix, and a cascade of others
The fix was to stop re-splitting. I kept an incremental index of where each line begins, updated from the edit metadata as the replay runs, so a position lookup became O(1) instead of O(file length):
// lineStarts[i] = byte offset where line i begins, maintained per edit
function offsetAt(lineStarts: number[], line: number, character: number): number {
return lineStarts[line] + character; // no split, no scan
}
I also stopped rebuilding the parallel provenance array on every edit and mutated it in place instead. There’s a property-based fuzz test that runs the new reconstructor against the old one over 1,000 random edit streams and asserts byte-identical output, because this code is load-bearing and I did not want to be quietly wrong about it.
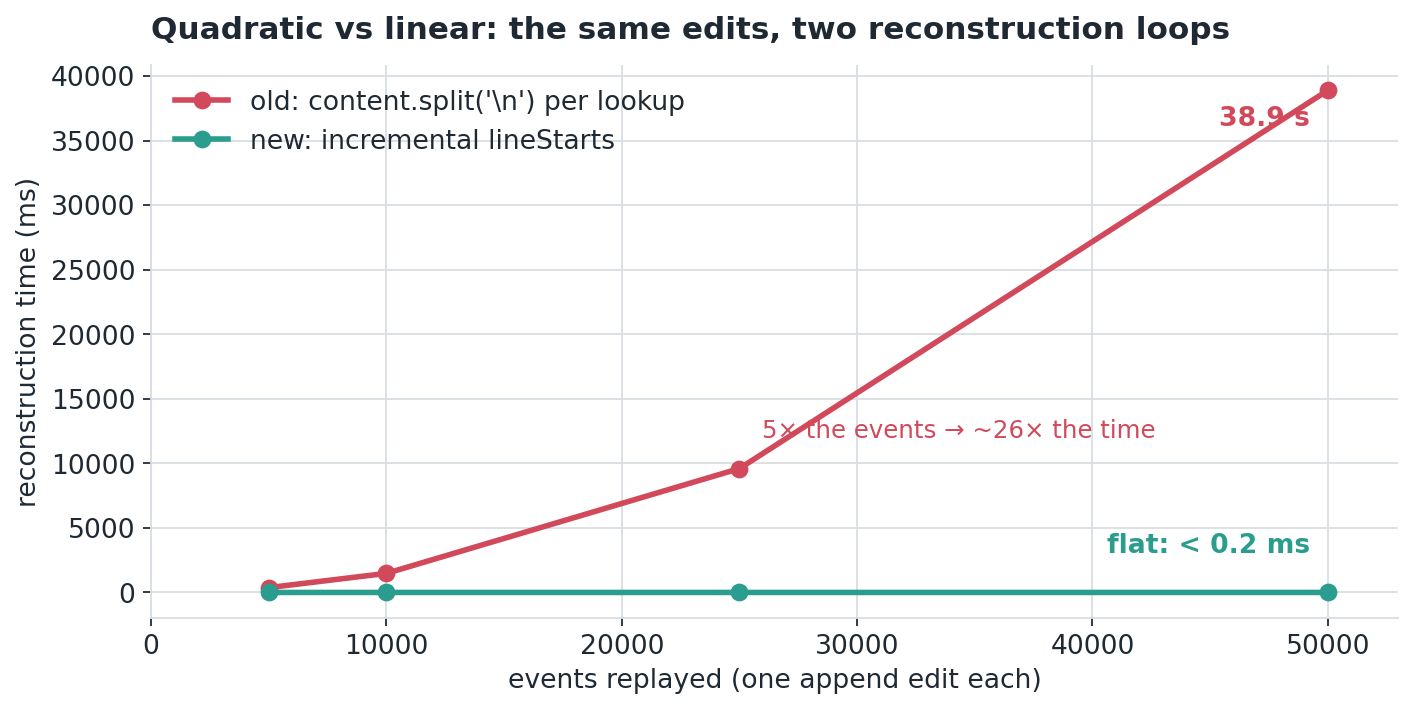
The exact bug in isolation: replay n append edits through the old split('\n')-per-lookup loop versus the incremental index. The old loop hits 38.9s at 50k events; the new one stays under a fifth of a millisecond. 5× the events gives ~26× the time, which is what quadratic looks like.
Same command, after the change:
$ INGEST_PROFILE=1 npm run profile:large -- 50000 # after the reconstruction fix
─── ingest profile · one 50k-event bundle ───
phase total share
parse_bundle 0.22s 6.7%
create_submission 0.22s 6.7%
run_heuristics 0.16s 4.9%
compute_stats 0.06s 1.8%
run_validation 0.24s 7.3%
materialize_events 2.37s 72.0%
──────────────────────────────────────────
handler_total 3.29s
A 50k-event bundle went from about 132 seconds to about 3.3 seconds, roughly 40×.3 The three formerly-quadratic stages all but vanished, and you can already see the cost sliding onto materialize_events, the actual database write.
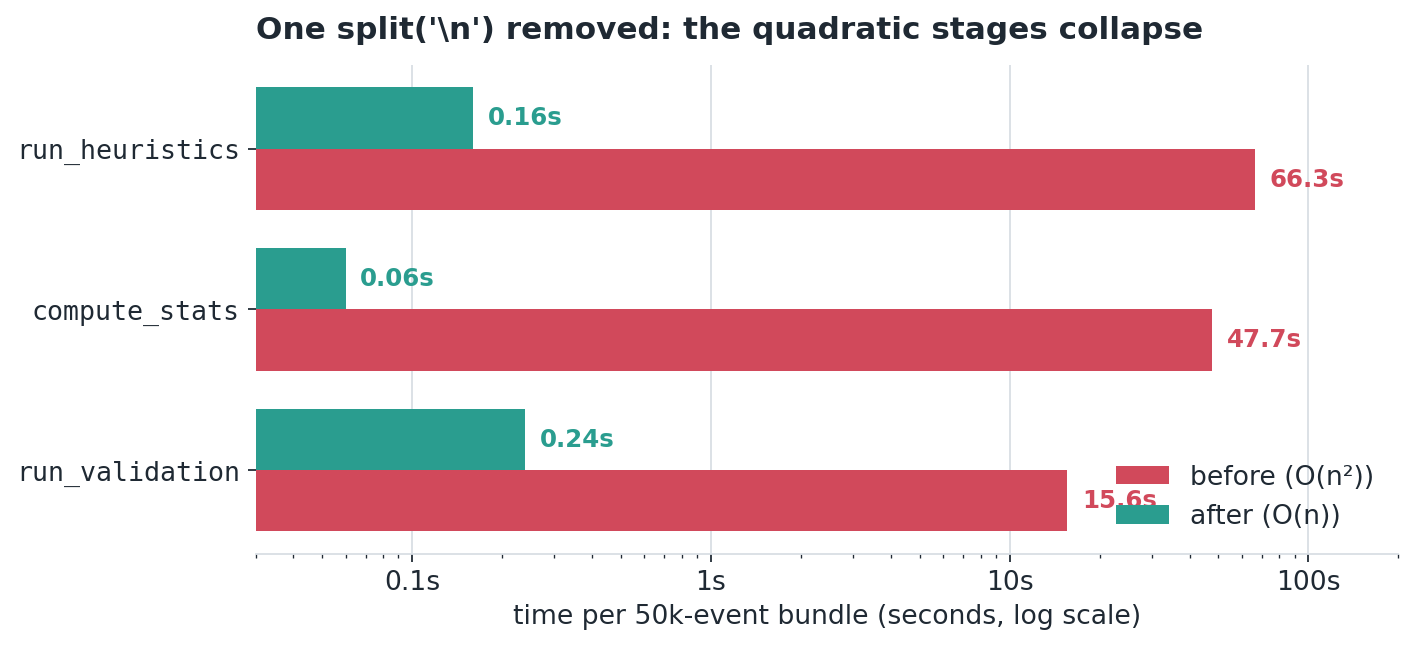
The three formerly-quadratic stages on one 50k-event bundle, from profile:large. Log scale, so each gridline is 10×. The database write (materialize_events, ~2.4s) was untouched and is what dominates now.
Once I was in there, I kept going. The row insert was the obvious next target. The old code chunked a parameterized multi-row INSERT a thousand rows at a time to stay under Postgres’s bind-parameter ceiling:
for (const chunk of chunks(rows, 1000)) {
await db.insert(events).values(chunk).onConflictDoNothing();
}
I replaced it with a single json_to_recordset INSERT that passes the whole batch as one JSON parameter. (Drizzle expands an interpolated JS array into a placeholder list, which blows the parameter cap, so a single json string sidesteps the entire problem.) I also prototyped COPY FROM STDIN, the textbook fast path for bulk loads, and benchmarked it dead even with the JSON insert at ~1.6s, because both pay the same index-maintenance cost on the way in. So I dropped the COPY plumbing rather than carry complexity that bought nothing.4
A few smaller wins rounded it out:
- Build the event index once per submission and thread it through the stages, instead of every stage rebuilding it.
- Worker concurrency to drain the job queue across cores. The 700-bundle import went from 348s to 87s to 44s at concurrency 1, 4, and 8 on my 10-core box, close to linear. (You have to raise the DB connection pool alongside it, or the workers just starve each other for connections.)
- Dropped a redundant index on the events table that was costing ~360ms per bundle of pure write overhead and buying nothing the primary key didn’t already give.5
BOOM. More error.
Feeling good about myself, I generated the real boss fight, 700 bundles at 50k events each, a 2.3 GB zip, and dragged it into the analyzer to upload. It died immediately.
My ingestion loaded the entire zip into memory before processing anything, and 2.3 GB sails straight past a ~2 GiB allocation ceiling buried in Node’s multipart parser.6 The error message was also a lie: a bare catch had been collapsing every failure into a generic “validation failed,” so I fixed that to surface the real cause while I was in there.
Two realizations came out of it:
- If you’re running this locally, there’s no reason to do the whole upload-into-memory dance at all. I added a local-path ingest that reads the export straight off disk with a streaming ZIP reader, so peak memory is one rebuilt bundle rather than the whole archive. A 10 GB+ export is fine now.
- Eventually this is a server, though, so I started on streaming the upload to disk and resumable, 50 MB chunked uploads, because losing your connection 10 minutes into a multi-GB upload and watching the whole thing vanish is a genuinely miserable way to spend an afternoon.
Along the way I also fixed a nastier little bug in the recorder itself. An edit made right after a save was getting logged as an external file change, because VS Code fires the change event before it flips the document’s isDirty flag, so the first edit on a just-saved buffer has the exact signature of a reload-from-disk.7 The fix gates that branch on a cheap synchronous disk check, and only on the first change after a buffer goes clean:
// a genuine reload converges to what's on disk; a real edit diverges from it
if (reason === undefined && !doc.isDirty && readFileSync(path, 'utf8') === doc.getText()) {
// treat as external reload
} else {
// normal keystroke edit
}
Late-night addendum (2:19 AM): I ran the full 2.3 GB ingest. It took 35 minutes. For a while I was sure it had hung, but it was just grinding through final processing without telling the frontend. Lesson learned: kick it off and go do something else.
Day 2: the optimization I almost missed
The next evening I found a sneakier version of the same kind of problem. My reconstruction was fast in the best case, when edits append to the end of the file, which is the pattern V8 keeps cheap and also, conveniently, the pattern all my benchmarks happened to use.
Real assignments don’t look like that. I remember my own CS 61A homework: you’re handed skeleton code with method signatures and you fill in the bodies, so almost every edit lands in the middle of the file. An interior edit in the old model copied the whole file body each time, which put me right back at O(L²) per reconstruction. And reconstruction runs about ten times per submission file, so it was ten interior quadratics stacked on each other, with heuristics taking the worst of it.
I added an edit-position knob to the benchmark so it could drop edits mid-file instead of at the end, with the same event count and same final file size. With edits landing in the interior the cost was 5.6× higher at 10k events and 12.1× higher at 25k (3 seconds versus a quarter-second for a single reconstruction).
Two fixes. First, a line-cell content model: store the file as an array of lines, each with its own parallel per-character provenance, so an intra-line edit rewrites a single line cell in O(line length) with no whole-file copy and no separate offset index to maintain. (It does regress pure whole-line insertion, since that shifts the cell array, but real keystroke streams are overwhelmingly intra-line typing, so it nets out well ahead. If real bundles ever prove me wrong, the documented next step is a gap buffer over the cells, which makes even that case linear.) Second, reconstruct each file once and share the result across every stat and heuristic that needs it, instead of replaying it from scratch per consumer.
Those got the reconstruction-heavy stages 3-4× faster on big files, and the win widens as files grow. Here’s the realistic workload measured at HEAD, infra-free, one doc.change per keystroke with an interior cursor:
$ BENCH_EDIT=methodfill npm run bench:stages -- 10000 50000
Absolute median ms per stage:
events slogMB fileKB parse buildIdx stats valid heur CPU sum
10,003 3.3 6.2 22.4 4.9 4.2 47.4 8.1 87.0
50,003 16.8 25.0 106.4 28.6 17.5 237.2 37.5 427.3
Normalized ms per 10k events (flat = linear, rising = super-linear):
events parse buildIdx stats valid heur CPU sum
10,003 22.37 4.87 4.22 47.41 8.12 86.98
50,003 21.29 5.73 3.50 47.44 7.50 85.46
The normalized columns are the thing to watch. Every one of them is flat from 10k to 50k events, which is what linear looks like. If reconstruction were still quadratic, the stats and heur columns would climb with size instead of holding steady.
I also handed Claude my actual CS 61A folder and the assignment format, and had it rebuild the fixture generator into a corpus-derived keystroke model: one doc.change per character, a real character mix, real auto-indent, ~3.5% newlines. Much more honest test data, and it confirmed the new code scales linearly where the old code went quadratic.
The part where the bottleneck moved
Then I ran the real thing, full stack, against a fresh Postgres + MinIO. (Wiping the dev volumes first handed me back 108 GB of accumulated test junk, which tells you something about how much CPU and disk this exercise had been quietly eating.) 700 bundles, 50k events each, 35 million event rows. It finished in about 17.8 minutes at concurrency 8.
$ INGEST_PROFILE=1 npm run profile:ingest -- --path large-700x50000.zip
# 700 × 50k, INGEST_CONCURRENCY=8, fresh Postgres + MinIO
─── ingest profile · avg per bundle (contended, c=8) ───
phase avg/bundle
handler_total 11.43s
├─ materialize_events 6.58s ◄ 50k row inserts per bundle
├─ create_submission 2.10s
├─ parse_bundle 1.24s
├─ run_validation 0.78s
├─ run_heuristics 0.29s
└─ compute_stats 0.22s
─────────────────────────────────────
700/700 matched · 35,002,100 event rows · Postgres → 22 GB
end-to-end: 1068.6s ≈ 17.8 min (0.66 bundles/s)
The reconstruction stages I’d spent the whole weekend on came in at under 2% of total ingest time. That sounds deflating until you remember those same three stages used to be about 90% of a bundle that took two full minutes. Heuristics alone went from 66 seconds to 0.16; stats from 48 seconds to 0.06. It’s super easy to write-off that work as a rounding error until you take a step back and see that it’s the only reason a 23-hour import is now a 17-minute one. The reason it reads as 2% NOW is that flattening it uncovered the cost that had been sitting underneath the whole time: writing rows to the database.
Materializing 35 million event rows, with eight transactions all contending on the same table’s indexes, is about 76% of what’s left. That cost was always there, just hidden behind a problem fifty times bigger. My CPU-only benchmarks never touched the database, which is also why my earlier estimate for this run was 24× too optimistic.
One asterisk worth stating plainly: I’m running Postgres and object storage locally through Docker-for-Mac, whose VM layer is famously slow at disk I/O, so the absolute numbers are probably the pessimistic end. The shape of it, DB-write-bound rather than CPU-bound, is what I’d expect to hold on real infrastructure.
And honestly, that’s a fine place to be. The CPU pipeline is at its algorithmic floor now. The one irreducible cost left is hash-chain verification, which is the entire tamper-evidence guarantee and isn’t allowed to get faster.8 Everything past that is a database-throughput problem, which is a much more boring and well-trodden thing to fix than an O(n²) hiding in three files.
The loose end: cross-flags
There’s one stage I haven’t beaten, the only truly super-linear one left. Cross-flags compares submissions against each other to catch shared pastes and cloned editing patterns, and it’s O(S²) in the number of submissions. On the 700×50k run it didn’t even finish inside my 5-minute poll window.9 It’s bounded by a small fingerprint per submission so it’s fine for normal cohorts, but at full fleet scale it’s the next thing to watch, and I’m torn on whether to optimize it now or shelve it until more people are on the project and can weigh in.
What I actually want to build next
The honest answer is that I shouldn’t be running this as one giant batch in the first place. If Provenance connected to Gradescope directly and pulled each submission as the student turned it in, the whole hour-long-import problem dissolves into a trickle of one-bundle ingests spread across the assignment window, each taking a couple of seconds, with nobody waiting on it. I’ve worked a lot with Gradescope’s (undocumented, delightful) API on other projects (see: AutoRemind), so a job that wakes up hourly, grabs new submissions, and ingests them feels very doable. It would also make populating the roster and the assignment list basically free.
For now, someone runs the import in the background and goes to lunch. It doesn’t need much babysitting, it just eats a frankly ridiculous amount of CPU and memory while it runs. The better way is incremental, and I know what it looks like; I just need the access and the green light to build it.
It was a long weekend. I killed a 40× quadratic, learned an embarrassing amount about how my own machine actually spends its time, and came out the other side knowing exactly where the next bottleneck is and what it’ll take to move it. I’ll take it.
-
The flag has to be set before Node starts, not inside the script, because ESM evaluates imports before the module body runs, which cost me a confused half hour. The subtler trap: a stale
npm run devworker pointed at the same dev Postgres quietly steals jobs from the profiler’s in-process worker and runs them somewhere else, so the phases you’re trying to measure just never show up. I once found one that had been up for 22 days, eating my numbers the whole time. ↩ -
There are three copies because the replay logic lives in three places: a plain-content reconstructor (stats and a couple of heuristics), a variant that also tracks a parallel per-character provenance array (most heuristics), and an inlined copy inside validation’s doc.save-hash check. A property test runs them against each other on random streams and asserts byte-identical output, which is the only reason editing them in lockstep isn’t terrifying. ↩
-
That 3.29s is the snapshot right after the reconstruction fix and nothing else. The bulk-insert and index-drop work later in this post shaved it further, so reproducing at HEAD today lands around 1.9s, with
materialize_eventsnear 1.0s. Same shape, lower floor. ↩ -
The fiddly part of even trying COPY was getting the raw postgres.js client out of the Drizzle transaction (
tx.session.client). Don’t wrap it back up withdrizzle(txSql)to reuse the query builder, because the tx client has nooptions.parsersand you get a baffling “Cannot read properties of undefined (reading ‘parsers’)”. I worked all of that out, benchmarked it neck-and-neck with the plain JSON insert, and deleted the whole thing. ↩ -
Measured by inserting 50k rows with different indexes present: primary key alone ~104ms, +
(submission_id, kind, t)~153ms, +(submission_id, session_id, seq)~517ms. That last index was ~360ms of pure overhead, and the primary key already orders rows by sequence, so it was dead weight. Bonus yak-shave:drizzle-kit generateis broken in this repo (a version mismatch), so I hand-wrote the migration and its journal entry, which turns out to be all the migrator actually reads. ↩ -
It’s not a limit anyone configured. Node’s
FormData/undici parser concatenates the entire request body into one contiguous buffer, and somewhere around 2 GiB that allocation just fails with aRangeError, well under the batch-size cap I’d set. The fix detects that specific failure and returns a real 413 that points you at the local-path ingest, instead of pretending it was a validation error. ↩ -
While I was in there I also caught a test-isolation bug that had been lying to me: the helper that finds the recorded log file returned whatever the directory listing surfaced first, so a test could read a stale log from a previous run. It now picks the newest file by modification time. ↩
-
It’s about 44% of the remaining CPU, and it has to be. Detecting tampering means recomputing
sha256(prev_hash + JCS-canonicalize(envelope))for every event and checking it still chains, where the JSON canonicalization is the expensive part. It runs exactly once per ingest and nothing else in the pipeline re-hashes, so there’s nothing to trim. You could shard it across worker threads, but that only helps the latency of one giant bundle, not the throughput of a class-sized import, which is the axis I care about. ↩ -
The “didn’t finish” is a measurement artifact, not a result: my harness polls for cross-flag rows for five minutes and then shuts the worker down, which cut the computation off mid-run. It is genuinely slow at that scale, though, because the feature extraction streams every submission’s events back out of the 35-million-row table. It’s debounced to run once per semester rather than once per submission, so in normal use you don’t feel it. ↩